Gallica : métadonnées quantitatives de la presse ancienne (XIXe-XXe siècles)
Présentation
Ce jeu de données contient des métadonnées quantitatives relatives aux contenus de la collection de presse traitée durant le projet européen Europeana Newspapers.
Contenu du jeu de données
Sept quotidiens nationaux et régionaux (1814-1945, 880 000 pages, 150 000 fascicules) des collections de la BnF font partie du corpus traité en OLR (Optical Layout Recognition) par le projet Europeana Newspapers (EN). Le traitement OLR consiste en la description (grâce aux formats METS/ALTO) de la structure de chaque fascicule et de ses articles (emprise spatiale, titre et sous-titre, classification des types de contenu).
De chaque fascicule numérique est dérivé un jeu de métadonnées quantitatives relatives aux contenus (nombre de pages, articles, mots, illustrations, publicités, etc.).

Ces métadonnées sont extraites du manifeste METS et des fichiers OCR associés (le jeu complet des métadonnées contient environ 5 millions de valeurs atomiques). Ce jeu peut alors être interrogé pour des activités de fouille de données.
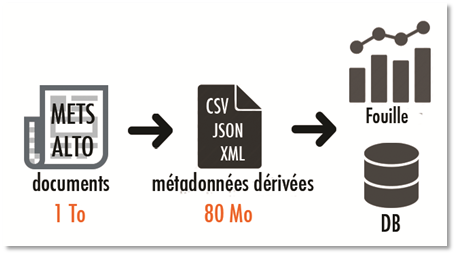
L’intégralité des documents numérisés dans Gallica des titres suivants sont présents dans le jeu :
- Le Gaulois : http://gallica.bnf.fr/ark:/12148/cb32779904b/date
- Le Journal des débats politiques et littéraires : http://gallica.bnf.fr/ark:/12148/cb39294634r/date
- Le Matin : http://gallica.bnf.fr/ark:/12148/cb328123058/date
- Ouest Eclair (éditions de Nantes, Rennes) :
- Le Petit Journal illustré supplément du dimanche : http://gallica.bnf.fr/ark:/12148/cb32836564q/date
- Le Petit Parisien : http://gallica.bnf.fr/ark:/12148/cb34419111x/date
Il est organisé par format (XML, JSON, CSV), par titre de presse et par date de publication. La structure de données utilisée est décrite pour chaque format dans un fichier readme.txt présent dans l’archive.
Contexte de production
Ce corpus a été produit à la suite du projet européen Europeana Newspapers (2012-2015) dans le cadre d’une activité de recherche décrite ici : http://altomator.github.io/EN-data_mining/
Liens de présentation du projet Europeana Newspapers :
- http://www.europeana-newspapers.eu/
- http://www.bnf.fr/fr/professionnels/projets_europeens/s.projets_europeens_termines.html?first_Art=non#SHDC__Attribute_BlocArticle1BnF
Formats
Les métadonnées sont exprimées selon trois formats au choix (XML, JSON, CSV). Dans chaque archive, un fichier readme.txt décrit le formalisme utilisé.
Exemples d'utilisation
- http://altomator.github.io/EN-data_mining/ (Jean-Philippe Moreux)
- http://vintagedata.org/these/supplement_europeana.html (Pierre-Carl Langlais)
API et jeux de données en relation
API
Le service web Gallica Issues permet d’obtenir les documents numériques d’un titre de presse à partir de leur date, et donc de connaître leur identifiant ARK (lesquels ne sont pas fournis dans le jeu de données). Elle opère avec comme entrée l’identifiant de la notice catalogue du titre de presse (fourni ci-avant, identifiant « cb… »). Exemple pour Le Petit Journal illustré Supplément du dimanche :
- Lister les années d’un titre :
http://gallica.bnf.fr/services/Issues?ark=cb32836564q/date
<issues compile_time="0:00:00.206" list_type="years" parent_ark="cb32836564q/date" total_issues="1899" uc3="no">
<year>1884</year>
<year>1885</year>
…
<year>1920</year>
</issues>
- Lister les fascicules pour une année (et obtenir les identifiants ARK) :
http://gallica.bnf.fr/services/Issues?ark=cb32836564q/date&date=1884
<?xml version="1.0" encoding="UTF-8"?>
<issues parent_ark="cb32836564q/date" list_type="issue" date="1884" compile_time="0:00:00.811">
<issue dayOfYear="167" ark="bpt6k7155522">15 juin 1884</issue>
<issue dayOfYear="174" ark="bpt6k715553f">22 juin 1884</issue>
<issue dayOfYear="181" ark="bpt6k715554t">29 juin 1884</issue>
<issue dayOfYear="188" ark="bpt6k7155556">06 juillet 1884</issue> …
A partir des identifiants ARK, il est possible d’afficher les documents :
- http://gallica.bnf.fr/ark:/12148/bpt6k7155522
- http://gallica.bnf.fr/ark:/12148/bpt6k7155522.thumbnail -- vignette
Jeux de données
Les jeux de données issus du même projet sont listés dans la rubrique Ressources.
Aide
Téléchargement des jeux de données
Les jeux de données sont mis à disposition sur un serveur FTP. En fonction du navigateur utilisé, le téléchargement est plus ou moins aisé.
L'accès au serveur FTP se fait sans difficulté avec Internet explorer et Edge. Il est plus aléatoire avec Firefox. Chrome interdit quant à lui l'accès aux serveurs FTP dans ses versions récentes.
L'utilisation de clients FTP comme le logiciel FileZilla est une autre solution pour récupérer ces fichiers.
Télécharger
Fiche Technique
Date de mise en ligne2016
Date de dernière mise à jourQuantité
880k pages, 150k fascicules
Formats techniquesXML JSON CSV
TechnologiesOCR OLR
SujetsPresse
LangueFrançais
Licence


